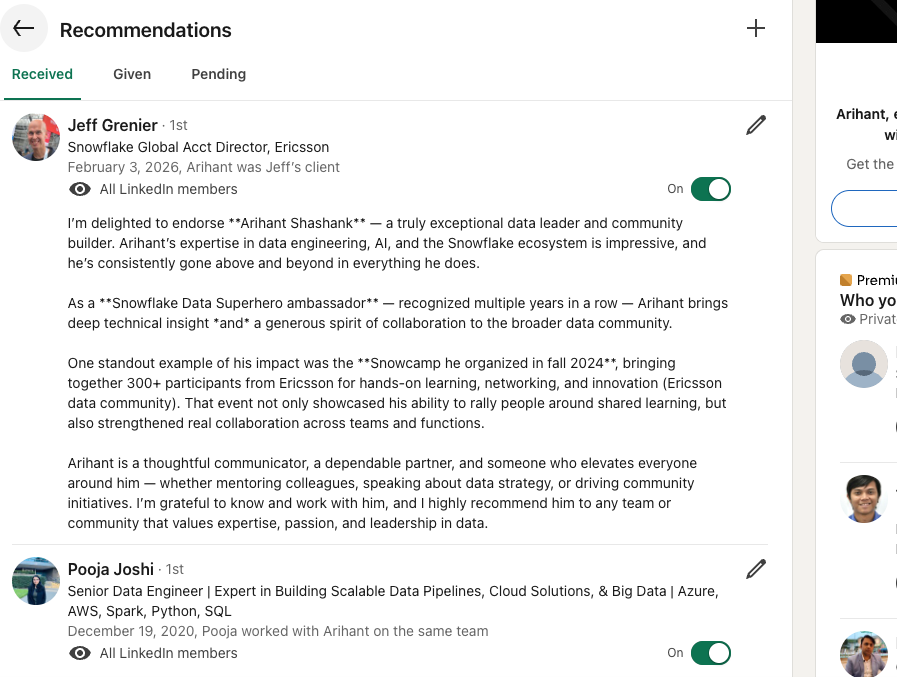
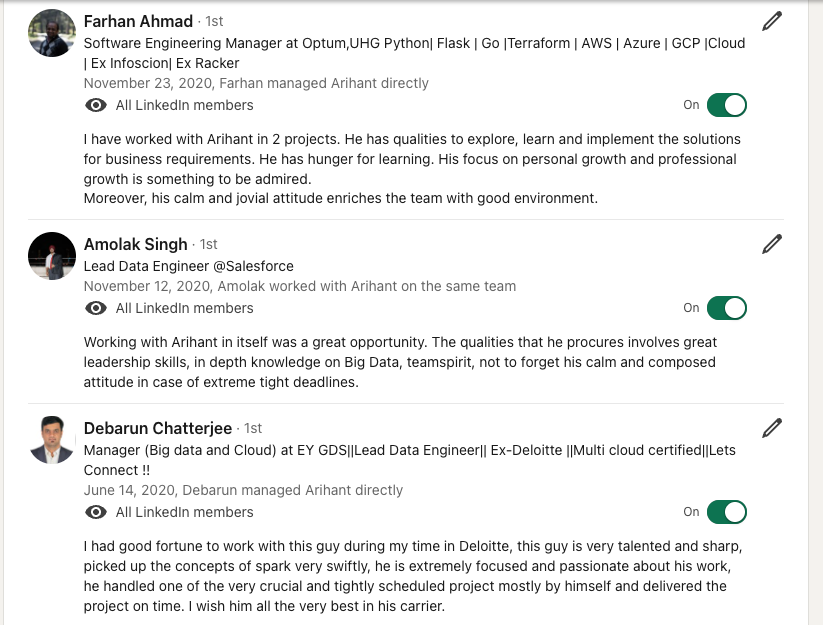
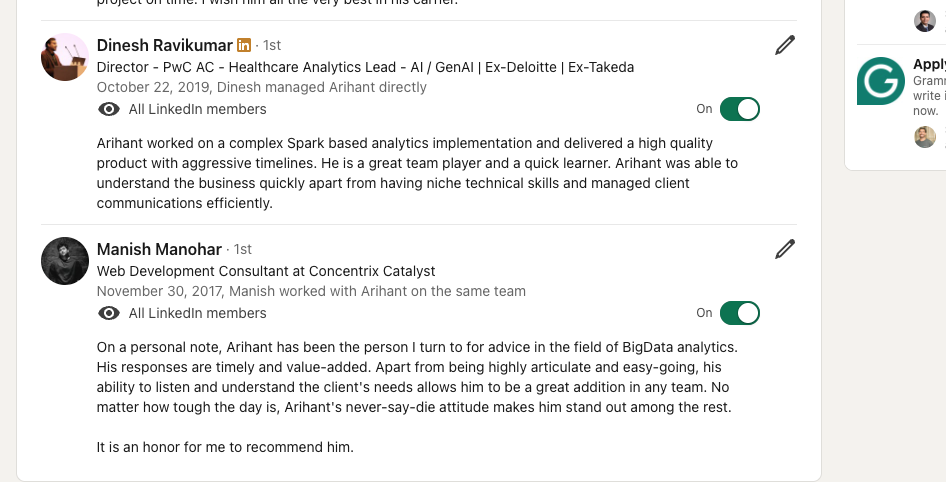
Available for Leadership Conversations
Arihant
Arihant
Shashank
Lead Data & AI Architect · Ericsson Global Chief Data & AI Office · Bengaluru
I architect the data & AI systems that power decisions,
productionize LLMs, and transform how enterprises operate.
Core Technologies & Skills
Snowflake
AWS
Generative AI & RAG
Data Architecture
Apache Iceberg
PySpark
LLMs & AI Agents
Airflow
Python
Vector Databases
Databricks